


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
第36回数値流体力学シンポジウム講演論文集(インターネット), 8 Pages, 2022/12
本論文では、運動論的プラズマシミュレーションコードを例としてC++ parallel algorithm (stdpar)による性能可搬実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。抽象化により性能可搬性を実現するKokkosや、指示行によって性能可搬性を実現するOpenMPとの比較により、stdparの性能,可搬性,生産性などを論じる。Intel Icelake, NVIDIA V100およびA100 GPUにおいて、stdpar版のアプリケーションの性能はKokkos版に対し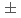 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、stdparはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
朝比 祐一; Padioleau, T.*; Latu, G.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
Proceedings of 2022 International Workshop on Performance, Portability, and Productivity in HPC (P3HPC) (Internet), p.68 - 80, 2022/11
被引用回数:0 パーセンタイル:0(Computer Science, Theory & Methods)本論文では、C++ parallel algorithmによる性能可搬な運動論的プラズマシミュレーションコードの実装について論じる。言語標準の並列アルゴリズムstdparと抽象的高次元配列mdspanにより、可読性および生産性を損なわずに性能可搬な実装が可能であることを示す。Intel Icelake、NVIDIA V100およびA100 GPUにおいて、アプリケーションの性能はKokkos版に対し 20%の範囲であった。将来的にAMDやIntel GPUにおいて利用可能になるという前提であれば、C++ parallel algorithmはエクサスパコンにおいて有力な高生産かつ性能可搬な実装手法となり得る。
今村 俊幸
Journal of Supercomputing, 15(1), p.95 - 110, 2000/00
被引用回数:2 パーセンタイル:30.03(Computer Science, Hardware & Architecture)本論文では分散メモリ型並列計算機に効果的な、縦ブロック分割の並列LU分解(VBPLU)について報告する。本手法は、ブロックアルゴリズムと通信の集団化という二つの最適化手法に基づいており性能向上が見込める。さらに長ベクトル演算を保障する点でベクトル計算機向けと予想できる。論文ではLog GPやSAD等で知られる並列化モデルに基づいた精密なモデル化を行うとともに、ブロック分割によって生じる負荷分散に関する一考察を与えている。さらに実機上での実験を通じてその結果の有効性を示し、スカラ機上で起こるキャッシュの問題について一解釈を与えることができた。VBPLUで行った解析手法は、ライブラリやコンパイラによるアルゴリズムの自動最適化に応用可能なものと考えられる。
川添 明美*; 高野 誠; 増川 史洋; 内藤 俶孝; 南 多善*
JAERI-M 91-066, 77 Pages, 1991/04
遮蔽解析精度の向上を目的として、遮蔽解析用モンテカルロコードMCACEの並列化を行った。効果的な並列化を行うため、MCACEの静的および動的なプログラム解析を行い、並列化のアルゴリズムを策定した。さらに、並列計算機の各セルの使用効率を向上させるため、それぞれの計算バッチを計算実行中に動的に空いているセルへ割り当てるなどの工夫を行った。並列化後のMCACEの性能評価を並列計算機のシミュレーターを使用して行った所各セルの稼動率がほぼ100%に近く、並列化が最大限行われていることがわかった。サンプル問題として、400粒子8バッチのものを全8セルの並列計算機上で実行させれば、約7.13倍の速度向上になることがシミュレーターにより予測された。
朝比 祐一; 長谷川 雄太; Padioleau, T.*; Millan, A.*; Bigot, J.*; Grandgirard, V.*; Obrejan, K.*
no journal, ,
一般に、実稼働可能な科学シミュレーションは、計算、通信、ファイルI/Oを含む多くの異なるタスクで構成される。GPUによる計算の高速化に比べて、通信とファイルI/Oは遅くなり、大きなボトルネックになりうる。これらのコストを抑えるためには、これらのタスクを並行して管理することが非常に重要である。本講演では、通信とファイルI/Oのコストをマスクするために、言語標準C++ senders/receiversを採用する。ケーススタディとして、局所アンサンブル変換カルマンフィルタ(LETKF)を用いた2次元乱流シミュレーションコードをC++ senders/receiversを用いて実装する。LETKFでは、模擬観測データはファイルから読み込まれ、その後、MPI通信とGPU上での密行列演算が行われる。このフレームワークによる性能移植が可能なことと、非同期処理による性能向上の効果を実証する。

